- 쿠키 쪽 복습하기 << 꼭 알아야함…
- @CookieValue << 이거 한번 정리해야함
Rest Client
- Client → Server (becomes client!) → Server
- The server becomes client → Rest Client
- 나중에 프로젝트 할 때 gpt api 등 쓸때 사용함 (근데 그냥 spring ai 사용할 수 있음 - llm service 여럿 추상화됨)
- CORS 알아야함 → 이번주 보충수업때 더 자세히
예외처리
- 우리가 처리하지 않아도 tomcat이 알아서 함
- 근데 디테일하지 않고 대략적인것만
- 우리 비즈니스 로직에 맞는 예외를 만들어야 함
전통적인 servlet
- http 직접 다루어야함
- servlet을 직접 다루게 되면 계층 나누기 어려움, 그래서 spring mvc가 등장해서 불리가 됨
작년?ㅂ터 java thread를 직접 다루게 되지 않게 됨 (virtual thread)
- 작년부터 배민<<<이 활용
- 쓰레드를 수만개를 사용 가능, 실시간 병렬처리
- web flux
spring에서 공식적으로 추천하는건 thymeleaf
reactive programming
-
blocking vs non blocking io
- blocking - 동기
- 어떠한 요청을 하면 쓰레드가 일함
- 하나의 쓰레드가 일을 하면 다른 쓰레드가 멈춰야 하는데, 이게 너무 커서 그냥 못느끼는거임
- 근데 어플리케이션이 어ㅓㅓㅓㅓ엄청 크면 딜레이를 느낄 수 있음
- 스레드 > c > s > r > db
- db에 장애가 있으면 거기에 대기해야함
- 그동안 스레드는 걍 대기중임 (낭비)
- 어떠한 요청을 하면 쓰레드가 일함
- non blocking io
- 안사용되는 스레드는 대기됨
- 스레드도 대기표같은게 있음, 알람이 오면 놀고있던 애가 처리를 함
- 병렬처리랑 다름
- 논블로킹을 위해서는 비공기 처리가 필요함
- 비동기 처리 → RxJava (비동기처리를 위한 기술)
- blocking - 동기
-
spring non blocking
- 아니요, 스프링이라고 해서 무조건 자동으로 논블로킹(Non-Blocking)으로 동작하는 것은 아닙니다. 어떤 기술 스택을 사용하느냐에 따라 다릅니다.
- 스프링 프레임워크는 크게 두 가지 방식으로 웹 애플리케이션을 개발할 수 있으며, 각각의 동작 방식이 다릅니다.
- spring mvc
-
- 기본적으로 블로킹(Blocking) 방식으로 동작합니다.
- 하나의 요청(Request)에 대해 **하나의 스레드(Thread)**가 할당되는 ‘Thread-Per-Request’ 모델을 사용합니다.
- 요청을 처리하는 동안 I/O 작업(데이터베이스 조회, 외부 API 호출 등)이 발생하면 해당 스레드는 작업이 끝날 때까지 대기(Blocked) 상태가 됩니다.
- 만약 동시에 많은 요청이 들어오고, 각 요청의 처리 시간이 길어지면 스레드 풀의 모든 스레드가 대기 상태에 빠져 전체 시스템의 성능이 저하될 수 있습니다.
- 예시: 사용자가 게시글 목록을 요청하면, 해당 요청을 처리하는 스레드는 데이터베이스에서 데이터를 모두 가져올 때까지 다른 일을 하지 않고 기다립니다.
-
- spring webflux
- chaining기 기본적
- 리턴값:
Mono<String>→ flux는 Mono를 쓰거나, flux라는 객체를 씀- Mono - 단일 데이터
- flux - 한번에 여러가지 데이터를 쓸때
- tomcat이 아닌 netty!
- 기술
- R2DBC - db에 접근하기 위한 기술<<
- webflux는 그냥 부캠 수료 후 공부하기.. 지금 볼 필요는 없음
-
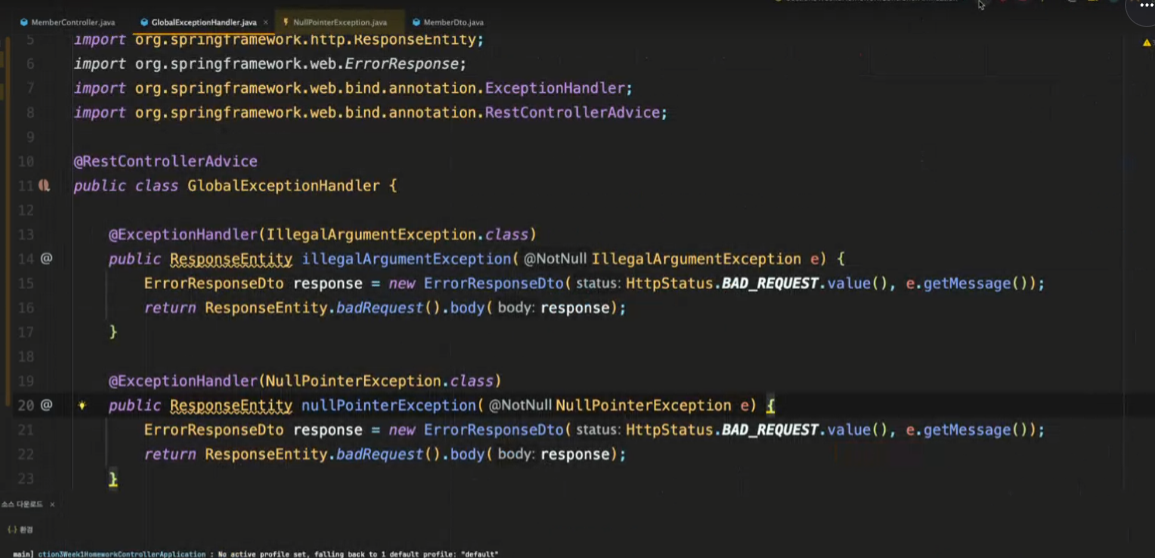
모든 예외는 동일한 형태로 반환해햐함
======================
- api CALL 이 느리다? 0.3초로 기준을 잡음
SLA
-
계약 같은거 - 고지하고 지켜야함
-
모니터링
- elk stack - elastic seach, 키바나?, 로그스탯
- 현재 운영적인 서비스가 있는지 확인 (spring에도 있는데 제한적이)
- infra - level
-
문서화
- spring rest docs 존재, 하지만 swagger이 가장 많이 쓰임
-
created일때는 보통 body는 비워둠
- 201 생성됨
-
삭제했을때 정보를 주는 경우가 없음
- 삭제하면 끝
- 204 no content사용하면 됨
-
sort는 기본적으로 수정해야함 (client가 요청 안해도)
필터링 정렬 페이지네이션 알아야함
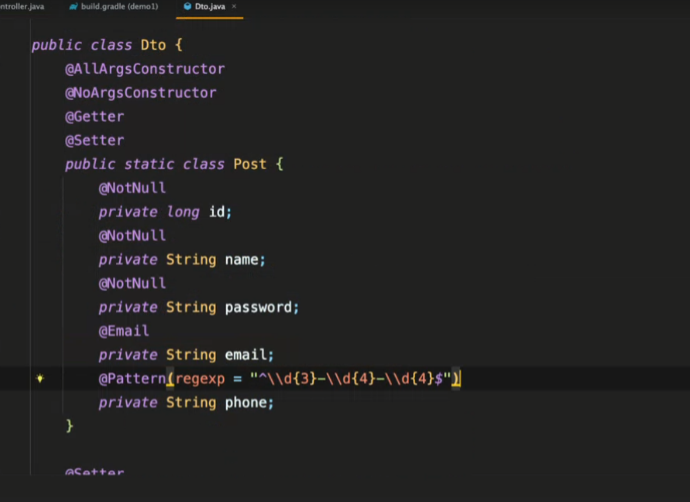
- DTO 설계 팁
- User class 만들고 그 안에 Response, Request 등 이너 클래스 만들기!!
- 어플리케이션이 커지면 이게 더 유용해짐
- User class 만들고 그 안에 Response, Request 등 이너 클래스 만들기!!
public class UserDto {
public static class Post {
private long id;
private String name;
private Stirng password;
private String email;
}
public static class Response {
private long id;
private String name;
private String email;
}
}
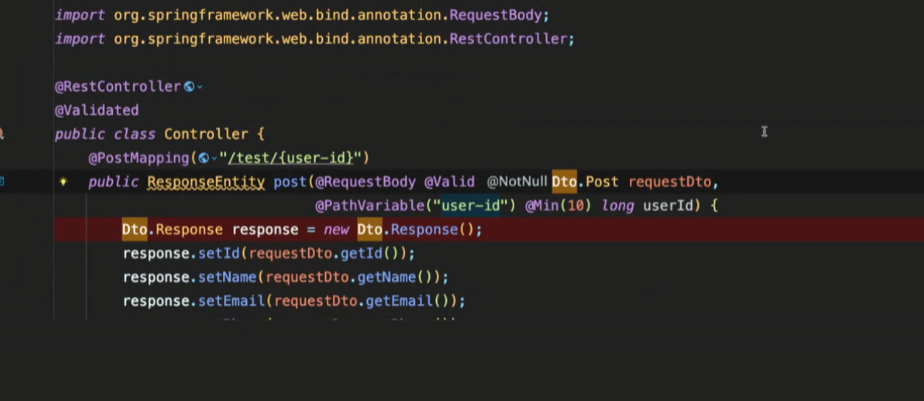
- 여기서 DTO를 받을때 request 때 Optional을 쓰면 안됨 (안티패턴임)
- 유효겅 검증 처리로 not null을 넣어야함
- 유효성 검증 어노테이션
- dto 안에 dto있을 때 거기도 @valid 있어야함
필터링과 정렬 패텀
GET - body에 암것도없어야함 <<<<<
- map으로 받아서 한번에 파싱할 수 있음
보통 에러 메서드 핸들러 만들때 정적 메서드 팩토리 패턴 씀
- 어떤 에러를 대처하려구
url 버젼 관리
- 복잡해질 수 있지만 많이 쓰임
- 날짜로 정리하기도 함
- 그냥 선택 차이임
api 버젼 관리
-
헤더로도 버젼 관리를 할 수 있음 → Accept부분 수정 (어떤 테이터를 받을지 결정하는 속성)
- 근데 이건 불편해서 활용도가 많이 높진 않음, 명시하는데 조금 어려움이 있음 (문서에 깔끔하게 정리가 안됨)
- 내부 시스템 (사내에 prvate으로 제공해서 사용하는 것)
-
URL 버젼 방식이 더 많이 쓰임
-
외우기 x
-
하위 호환성 유지
- 변경에 자유로워야 한다 → 유연한 설계
요청과 응답이 어떻게 달라지는지 정확히 예시까지 포함되어있는데 가장 좋은 문서임
API 품질 (성능)
- 주요 성능 지표
- 가장 중요한건 latency 자연 시간임
- 예시 >
- findalll 은 가장 위험한 코드임
- 성능에 아주 치명적임
- 처리
- pagination 처리 (spring data,, jpa) → Pageable객체를 사용
- limit < ?
- 기본
- 캐싱 redis
- 직접 dto에 맞는 query문 짜기도 함
- pagination 처리 (spring data,, jpa) → Pageable객체를 사용
- findalll 은 가장 위험한 코드임
- query tuning
- 캐싱 전략을 바꾸거나 인덱스 설정을 하거나 등등
- 개발자가 토드 레벨에서 적용할 수 있는 건 pagination, 지연 로딩 방지
- jpa orm을 사용할때 나타나는 가장 고질적인 문제 N+1
- 무조건 해결해야하는 문제. 나중에 익숙해지만 “아 이거 n+1 터지겠네” 하고 눈에 보임
- jpa orm을 사용할때 나타나는 가장 고질적인 문제 N+1
tip
- API 응답 시간은 보통 200ms (0.2초) → 가장 이상적
- static resources 부터 캐싱
- dto는 필요한 데이터만
api 버젼
- 컨트롤러를 2개 만들어서 구현
- 버젼관리할때 DTO같은 경우 필드수정/추가가 필요 → v2는 예전꺼, 새로운거 둘다 반환함, 예전꺼는 @Deprecated를 사용해서 언제까지 사용할 수 있는지 써져있음
- 실제로 버젼관리를 하는 일이 많지 않음, 외부의 개발자에게 제공해야할때 사용
- or open source에 기여할때
문서화
spring rest docs
- 테스트 코드를 기반으로 자동으로 문서 만듬
- 테스트 코드가 통과되어야지 됨 (보장됨) > 근데 이게 단점이 되기도
- 테스트가 필수임. 모든 기능이 개발되어야함. 기본저긍로 테스트 코드 짤 줄 알아야함. 슬라이스 테스트!
- TDD, Mockito 사용해야함…
- 테스트가 필수임. 모든 기능이 개발되어야함. 기본저긍로 테스트 코드 짤 줄 알아야함. 슬라이스 테스트!
- 근데 사용법은 익혀두면 좋음 (spring에서 가장 support함… 근데 많은 사람들이 주류로 사용하지는 않음)
.adoc- snippet
TDD를 잘하면 정말 잘게잘게 작은 단위로 나울 수 있음
- learning curve높음 (mockito같은거 잘써야함)
- 어느 시점에서 어떤 테스트 객체가 필요할지 미리 생각하고 코드 작성 > 경험 기반. 어려움!
슬라이스 테스트 ( 컨트롤러만)
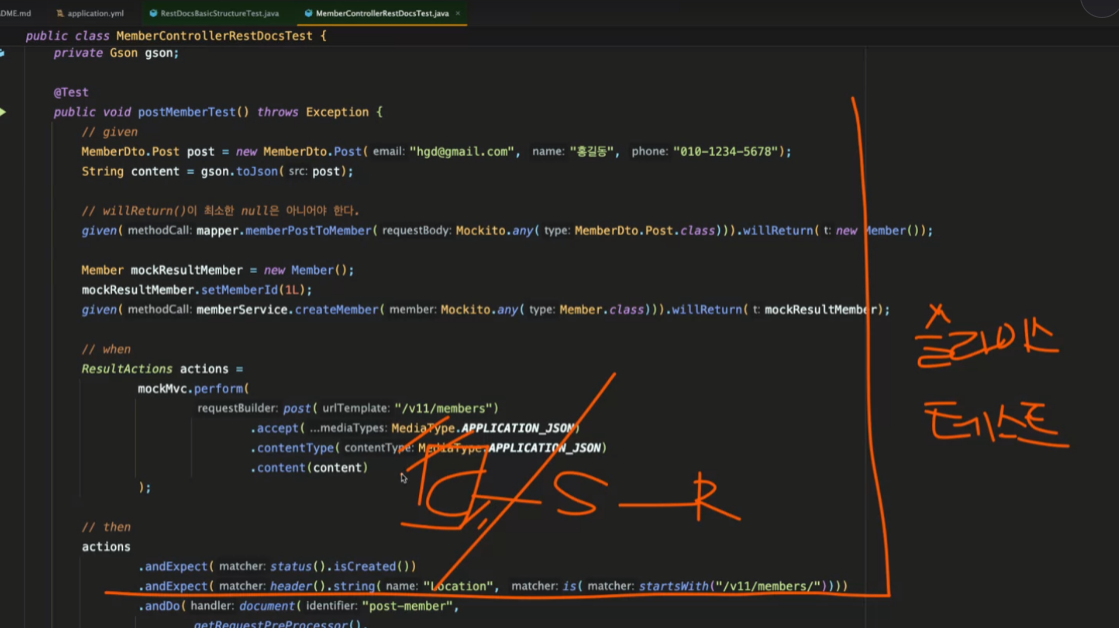
swagger ui
controller + dto 관련 문서화
- 더 많이 씀, 당장 익숙해져야함 (이번 과제에 있음)
- 정적파일 x, 브라우저
- openapi →swagger 기능 포함 (
build.gradle에 의존성만 추가하면 됨) - yml
- swagger ui 부분은 꼭 켜야함
- GroupedOpenApi - > MSA에서 많이 쓰임 (과제에선 필요x)
- schema, tag, operation, 설정
- tag, operation 은 컨트롤러
- controler + dto에 직접 코드를 넣어야함
- 테스트 코드 없어도 됨, 그냥 테스트를 못할 뿐
결국 코드 기반으로 문서가
- 베포 자동화 파이프라인을 구축하면, 자동으로 문서를 최신화할 수 있음
- 코드 갱신 → 깃험 → 문서 갱신
-
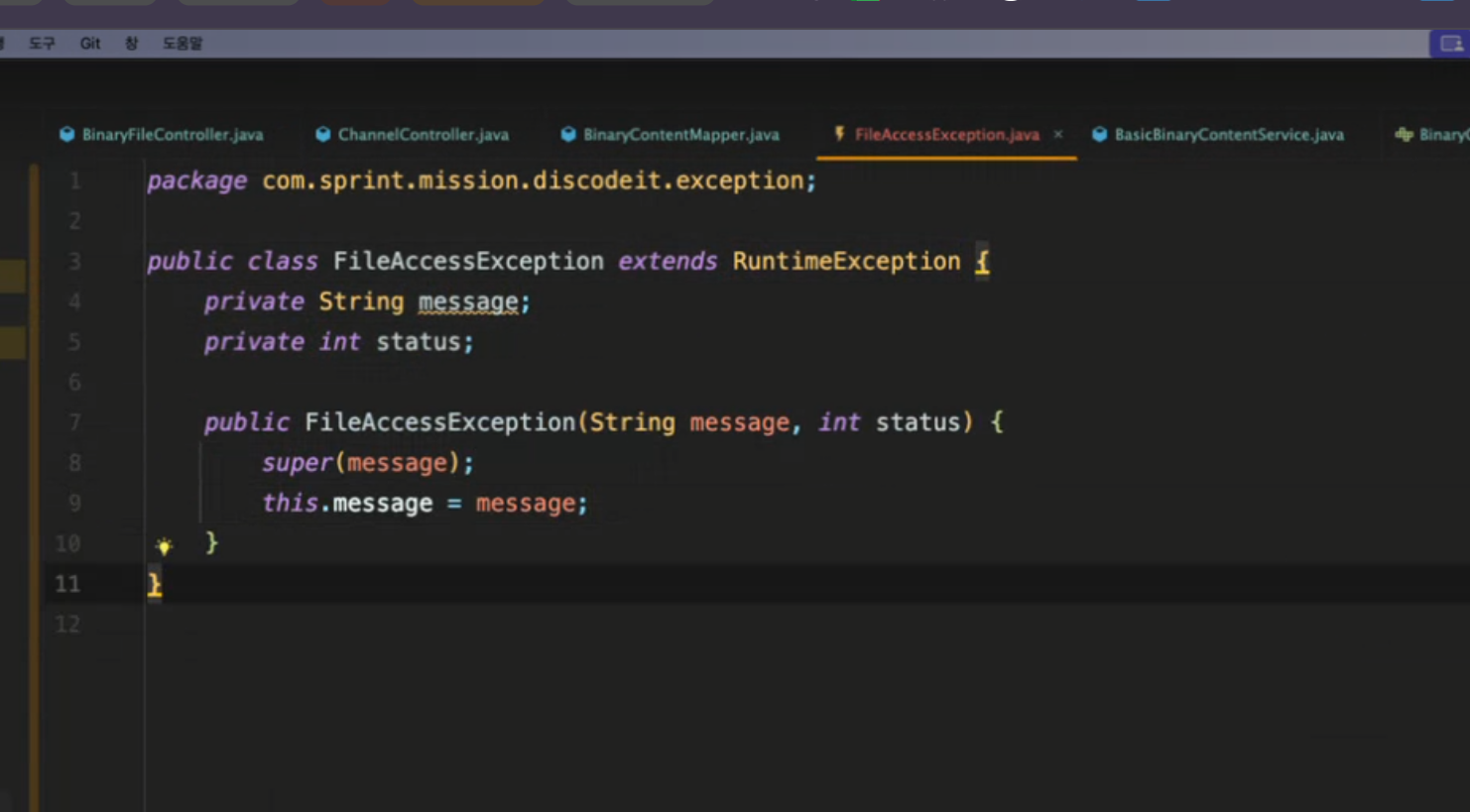
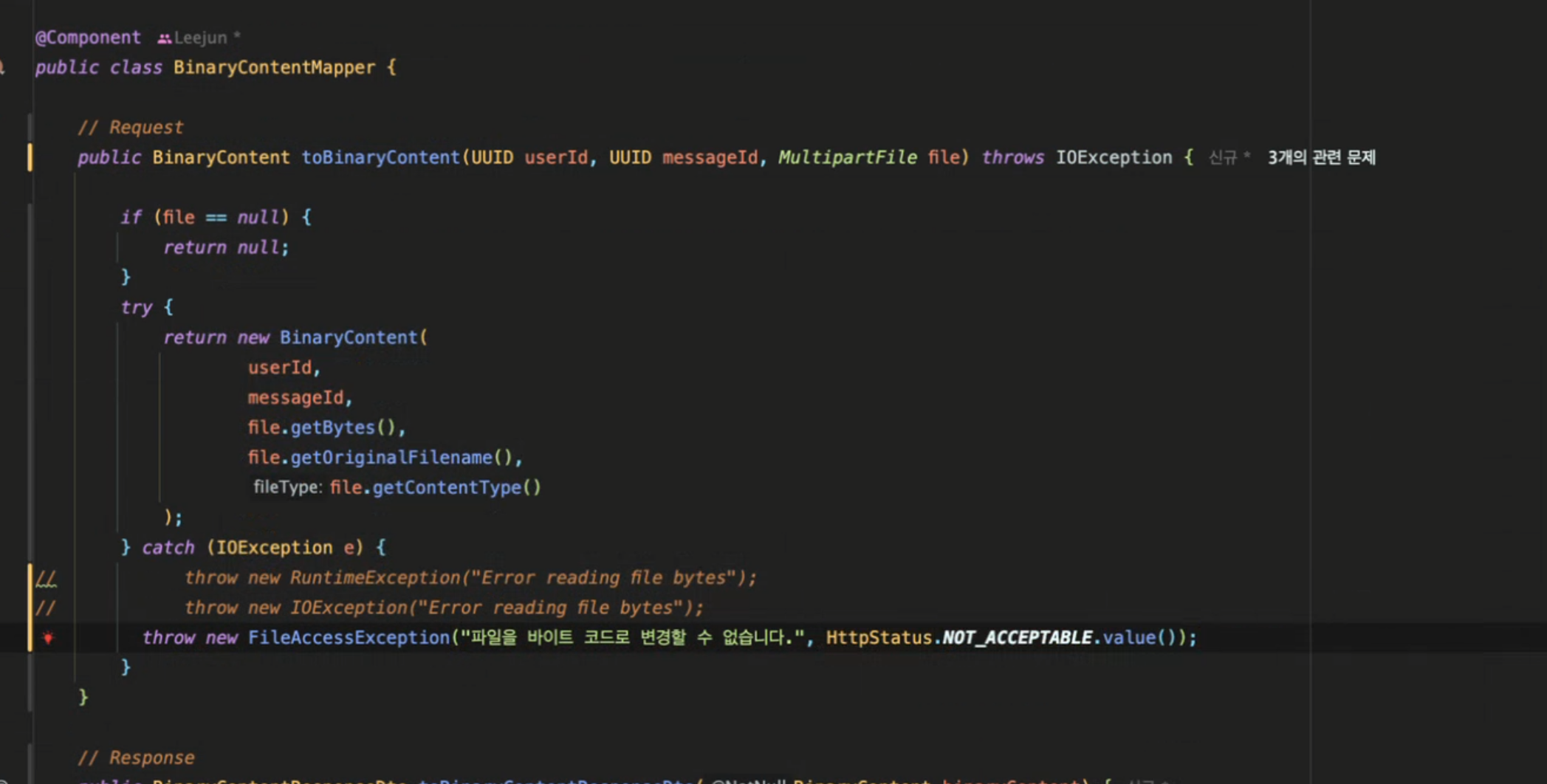
transactional을 하기 위해서!!!!!!!!<<<< 이거 정리하기!!!!
-
unchecked vs checked
- checked - 개발자가 직접 핸들링
- unchecked - 런타임
-
나중에 @Transactional 어노테이션을 컨트롤러 계층에서 사용하고 싶은데 그려려면 unchecked exception을 던져야 한다고 배웠었습니다. IOException은 checked excpetion이기 때문에, FileAccessException 클래스를 따로 만들고 여기서 대신 던져줬습니다!