Process of grouping unlabeled data based on similarities and differences
- Some algorithms
- K-means
- K-medoids
- density based
- hierarchial
Example 1
- Continued breast cancer classification
- We don’t know if any of the tumor in the dataset is benign or malignant
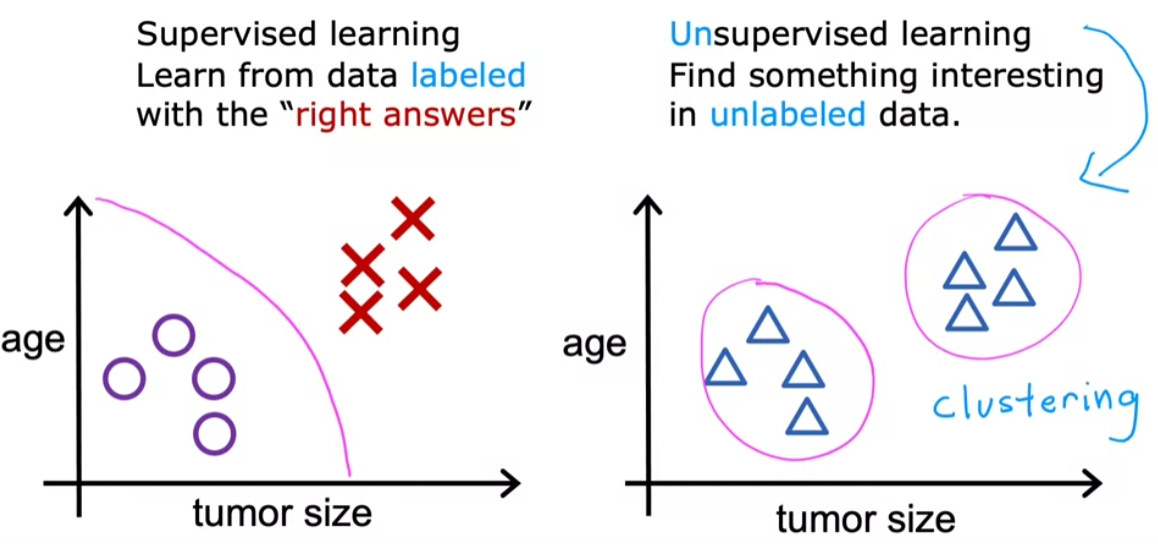
- The algorithm can assign out data to 2 different groups/different clusters
Example 2
- Google news
- Looks at 10000s different news and ‘groups’ them together