HTTP
HyperText Transfer Protocol
- Communication flows primarily from client → server, with server responses back to client
- HTTP methods are universal across all programming languages and frameworks
- The same methods (
GET,POST,PUT,PATCH,DELETE) work identically whether you’re using Python Flask, Node.js, Express, or any other framework- If you don’t understand this… you’re not a backend developer lol
- Client-side and server-side
- In the 7th Application layer in the OSI 7-layer model
- How is this related to TCP IP <<<<
- Implementations
Web API Components
| Component | Description |
|---|---|
| URL | Which resource to request (e.g., /users/1). |
| Method | The type of action to perform (GET, POST, PUT, DELETE). |
| Status Code | The result and state of the request (e.g., 200, 404, 500). |
| Body | The request or response data (e.g., JSON, XML). |
Characteristics (정리하기)
- Main traits
- Statelessness
- Connectionless
- Caching support
- Because of these traits, it’s not real-time (you need to refresh)
- Web sockets handle this problem
Statelessness (무상태성)
- The server treats every single request as a brand new, independent event.
- It has no memory of any previous requests you’ve made
- This stateless nature makes it much easier to scale the server (scale-out) and simplifies load balancing
- Advantage: Scalability.
- Because the server doesn’t need to store information about past conversations, it’s very simple. Any request can be sent to any server in a large system (like Google’s or Facebook’s), making it easy to handle millions of users.
- Disadvantage: You can’t have a “conversation.”
- How do websites keep you logged in or remember items in your shopping cart if the server forgets you every time?
- This can be fixed by building state on top of HTTP. Client sends a “reminder” → this is what cookies and authorization tokens are for
Connectionless (비연결성)
- When you make a request, a connection is made, the server sends a response, and then the connection is immediately closed.
- The steps
- Client connects to Server.
- Client sends request.
- Server sends response.
- Connection is terminated.
- Why? → It’s efficient.
- The server doesn’t have to keep thousands of connections open and waiting, which would use up a lot of resources.
- It just serves the request and moves on.
Caching support (캐싱)
- HTTP provides built-in support for caching. By using headers like
Cache-Control,ETag, andLast-Modified, developers can reduce unnecessary requests, which significantly improves performance.
HTTP Request Methods
From the client’s perspective making requests to servers:
- They’re just conventions & rules. Not all companies might follow them, for example they can just use only
POSTbecauseGETor other methods can expose data (but this is uncommon) - Just…need to memorize this lol
| Method | Description | Characteristics | Common Examples | Body | Idempotency |
|---|---|---|---|---|---|
| GET | Request/retrieve a resource from server | • Cacheable • Safe operation (doesn’t change server state) | • View homepage • Get user profile • Fetch blog post list • Download HTML/text/data | • No body required • Normally has NO body - you can’t even include it if u wanted | ✅ |
| POST | Send new data to server (create something) | • Not idempotent (multiple requests = multiple resources) • Creates new resources | • Submit signup form • Create new blog post • Send email & password • Upload file | • Body required | ❌ |
| PUT | Replace entire resource with updated version • Ex. Using put method in map | • Idempotent • Creates resource if it doesn’t exist • Must send ALL data for the resource | • Update complete user profile • Replace entire blog post • Overwrite file completely | • Body required | ✅ - same result if repeated |
| PATCH | Partially update resource | • More efficient than PUT • Only sends fields you want to update | • Change just the blog post title • Update only password • Modify user’s email only | • Body with only changed fields | ✅, ❌ - it depends |
| DELETE | • Remove resource from server/database • Common to delete with a UUID (식별자) | • Request from client to server to delete something | • Delete blog post • Remove user account • Cancel subscription | • Usually no body | ✅ |
Caching
GETrequests are cacheable
- Caching = Temporary storage of frequently used data to avoid repeated server requests
- Browsers, proxy servers, and Content Delivery Networks (CDNs) can store the response to a
GETrequest- GET requests don’t change data (they’re “safe”)
- 1st request vs 300th request = same data returned
- Perfect for caching since the data doesn’t change
- Trade-off
- Gain: Better performance (faster responses)
- Cost: Less real-time data (might show slightly outdated info)
- Implementation
- Redis - popular tool for easy caching implementation
GET VS POST
- Something you should know immediately when asked!
| Category | GET | POST |
|---|---|---|
| Request Purpose | Data Retrieval | Data Creation, Submission |
| Request Data Location | URL Query String | HTTP Body (JSON/Form, etc.) |
| Request Body | None | Exists |
| URL Length Limit | Exists (Browser limit of 2,048 characters) | None (Theoretically unlimited) |
| Caching | Possible (Browser/Proxy Server) | Fundamentally not possible |
| Idempotency | O (Idempotent - multiple identical requests have the same effect) | X (Not Idempotent - repeated requests may create duplicate resources) |
| Browser Back/Refresh | Safe | A new request is re-submitted (potential for re-registration) |
| Security | Relatively low (data exposed in the URL) | Relatively high (data included in the body) |
Get- The reason why body doesn’t exist in
GET- its fundamental purpose is to retrieve data from a server, and all the information required to identify that data is intended to be contained within the URL itself
- Idempotent
- making the same request multiple times has the same effect as making it once
- a “read-only operation”
- The reason why body doesn’t exist in
POST- get,post,put,delete 같은 것들보단 애매한것들을 처리하는 경우가 많음
GET VS POST for Login?
Login
When implementing a login feature, use
GETorPOST? → UsePOST!
- Using GET?
- Bad idea. While technically possible, it leaks credentials (username, password) directly in the URL.
- This is a major security risk (visible in browser history, server logs, etc.).
- Why POST is Correct:
- Security: It sends data in the request body, not the URL.
- Semantics (The Deeper Reason): Login is more than just fetching data. It’s an action that creates a new resource.
- Resource → An “authentication token” or a “user session.”
- Therefore, login is the creation of an authenticated identity for that session.
Idempotency
Idempotency
An operation is idempotent if performing it multiple times produces the same result as performing it just once.
- the state of the system and the outcome must not change, regardless of whether it is executed 1 time or 100 times
- It’s about ensuring that the side effects of an operation are not repeated if the operation itself is repeated
- A related example: Pure function (순수 함수)
- Java’s hash functions
- (면접에서 나올 수 있음)
- Idempotent methods
GET- Requesting the same resource multiple times returns the same result
- Reading data doesn’t change server state
PUT- Overwriting the same resource with the same data multiple times results in the same final state
- Ex) Updating your address to “123 Main St” 5 times still results in address = “123 Main St”
DELETE- Deleting an already deleted resource maintains the same state (resource stays deleted)
- Ex) I instruct the server to DELETE my subscription 100 times. No matter how many times the operation happens, the result is that my subscription is deleted.
- NOT idempotent
POST- Each call can create a new resource
- Ex) Submitting a “create user” form 3 times might create 3 different users
- Depends
PATCH- ✅ Idempotent PATCH:
{"name": "John"}- setting name to “John” multiple times = same result - ❌ Non-idempotent PATCH:
{"age": "+1"}- incrementing age multiple times = different results
- ✅ Idempotent PATCH:
HTTP Request Structure/Response
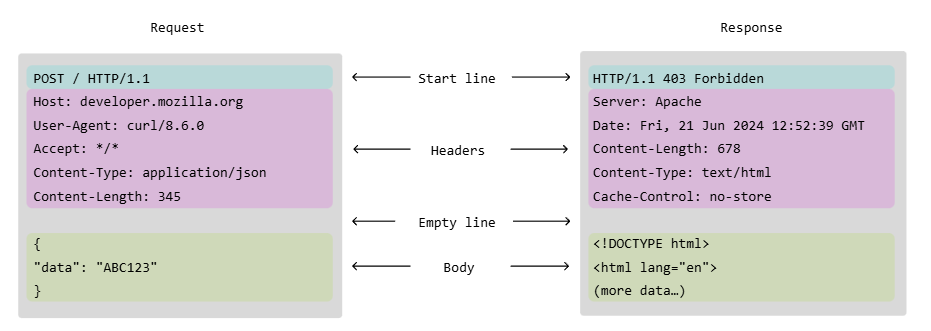
- This is a universal format
| HTTP Request | HTTP Response | |
|---|---|---|
| Start line (request line) | HTTP Method + URL + HTTP Version Example: GET /users HTTP/1.1- GET = HTTP Method (what action to perform)- /users = Path (what resource you want)- HTTP/1.1 = HTTP Version (which version of HTTP protocol to use) | HTTP Version + Status Code + Reason Phrase Example: HTTP/1.1 200 OK- HTTP/1.1 = HTTP Version (same as request)- 200 = Status Code (numerical code indicating what happened, never in request)- OK = Reason Phrase (human-readable description of the status code) |
| Headers | Metadata about the request | Metadata about the response |
- Host: The domain name of the server (e.g., api.example.com, or local server). Required. - User-Agent: Identifies the client software sending the request (e.g., Chrome, Postman).- Accept: Tells the server what content formats the client can understand for the response (e.g., application/json).- Content-Type: Specifies the format of the data in the request body. Essential for POST/PUT requests (e.g., application/json).- Authorization: Contains the credentials to authenticate the client (e.g., Bearer <token>).It’s typical to add in Content-Type and Accept | - Content-Type: Specifies the format of the data in the response body (e.g., application/json).- Content-Length: The size of the response body in bytes. - Set-Cookie: Used to send a cookie from the server to the client. - Server: Information about the server software (e.g., nginx). | |
| Empty Line | --- | ---- |
| Body | Data sent with the request - Required for POST and PUT, contains the resource to be created or updated.- Optional/Empty for GET, DELETE, etc. | Data returned by the server - Examples: HTML page, JSON data, file content - Optional, may be empty (e.g., for a 204 No Content response). |
- The reason why we need empty line
- We don’t know how many lines are the header
- There is NO empty line after start line because start line is guaranteed to be 1 line
- Request VS Response
- Response - Start line: no method + status code
Headers
- It’s stored as a Key + Value pair, you can even create custom ones (but are rarely used)
- Essential parts:
AcceptandContent-type
| Header | Role | Description | Example |
|---|---|---|---|
Content-Type | Defines the data format of the request body | Tells the recipient what format the data in the body of the current message is in - Both in request and response | application/json, application/x-www-form-urlencoded |
Accept | Requests the response data format | Used by the client to tell the server what data formats it is willing to receive | application/json, text/html, application/xml |
| Example |
// ============= REQUEST =============
GET /api/users/123
Host: example.com
Accept: application/json
// ============= RESPONSE =============
// header
HTTP/1.1 200 OK
Content-Type: application/json
// body
{
"id": 123,
"name": "Alex",
"email": "alex@example.com"
}Main Content-Type
| Type | Description | Usage Examples |
|---|---|---|
application/json | JSON format data | Most REST API requests/responses |
application/x-www-form-urlencoded | Standard encoding for HTML form submissions | Login, user registration forms, etc. |
multipart/form-data | Used for uploading files | Uploading images, attachments |
text/plain | Plain text | Simple text messages |
application/xml | XML format data | Integrating with legacy systems, etc. |
Body
- Just think that there is the remaining data that is not in header
Flow
- Client sends request:
GET /users HTTP/1.1(no status code here!) - Server processes request
- Server sends response:
HTTP/1.1 200 OK(status code appears here!)
Examples - Request
Examples of Raw HTTP Request
HTTP Request - GET
GET /users HTTP/1.1
Host: api.example.com
Authorization: Bearer <token>
Accept: application/jsonHTTP Request - POST
POST /users HTTP/1.1
Host: api.example.com
Content-Type: application/json
Authorization: Bearer <token>
{
"name": "John Doe",
"email": "john@example.com"
}Status codes
Status codes communicate what happened with the request:
- Resources
- The cheatsheet

- Basically
- 2xx Success -
200 OK(most common success) - 3xx Redirection
- 4xx Client Error - Client made a mistake
- 5xx Server Error - Server had a problem
- 2xx Success -
- In 🐣Spring & SpringBoot
- status codes are stored as enums
- You can even create one for yourself if necessary
- automatically returns appropriate status codes
- you may see a lot of 500 Internal Server Error
- Unhandled exceptions occur in your code
- Configuration issues (database connection fails, etc.)
- Poor error handling - if you don’t properly handle exceptions, they become 500s
- status codes are stored as enums
| Category | Range | Description |
|---|---|---|
| 1xx | 100–199 | Informational (Rarely used) |
| 2xx | 200–299 | Success (Request successfully processed) |
| 3xx | 300–399 | Redirection (Indicates a redirect to another location) |
| 4xx | 400–499 | Client Error (Problem with the request) |
| 5xx | 500–599 | Server Error (Internal server problem) |
- It’s good to send specific status codes
- If a request is successful and you’ve used
POST, it’s more accurate to send201than200200- successful request201- resource successfully created
- If a request is successful and you’ve used
Practical tips
- 2xx Codes: While 200 OK is the default for most successful responses, it’s better to be more specific with codes like 201 Created (when a resource is created) or 204 No Content (when the action is successful but there’s no data to return).
- 400 Bad Request: Use when the client’s request is invalid due to a syntax error, malformed request, missing parameters, etc.
- 401 Unauthorized: Use when authentication is required but is missing or incorrect (e.g., a missing or invalid token). This is an authentication failure.
- 403 Forbidden: Use when the user is successfully authenticated but does not have the necessary permissions to access the specific resource (e.g., a standard user trying to access an admin API). This is an authorization failure.
- 404 Not Found: Use when the client requests a resource that does not exist on the server.
- 500 Internal Server Error: A generic catch-all for when an unexpected exception occurs in the server-side code. It’s a critical status code that signals an urgent need for server-side debugging.
Path Variables VS Query Parameters
- Example:
https://example.com/users/123/orders?status=shipped&sort=date/users/123/ordersis the Path.- The
123inside the path is a Path Variable. ?status=shipped&sort=dateis the entire Query String.status=shippedis a Query Parameter.
| Feature | Path Variable | Query Parameters |
|---|---|---|
| Purpose | To identify one specific resource. | To filter, sort, or search a list of resources. |
| Structure | Part of the URL path (e.g., /users/123) | Key-value pairs after a ? (e.g., ?gender=F) |
| When to Use | You need exactly one thing. | You have a list and want to narrow it down. |
| Is it required? | Yes. The URL is broken without it. /users/ is not the same as /users/123. | No. They are optional modifiers. /users is valid on its own. |
Export to Sheets
Practical Tips
- When designing your APIs, always build them to be stateless
- each request should be able to operate independently without relying on stored session information from previous requests
- When designing an API, you should always instruct clients to explicitly specify the
AcceptandContent-Typeheaders. - In Spring, if a request is sent with an unsupported
Content-Type, it will result in a415 Unsupported Media Typeerror. - If you want to handle various formats for the response body, utilize the
producesattribute in your mapping annotation (e.g.,@RequestMapping,@GetMapping). - Keep your
JSONresponse formats consistent across your entire API - Specifying the request and response formats for each API in your Swagger (
OpenAPI) documentation can significantly reduce confusion for developers using your API. - Using REST APIs for server-to-server communication is highly advantageous, as it makes it much easier to expand into a distributed architecture later on.
[!💡Summary]
- HTTP is the foundational communication protocol for web applications. Understanding its request and response structure is the starting point for all API development.
- Choosing the right methods, understanding status codes, and specifying data formats (
Content-Type/Accept) are all essential elements in practical API design and debugging.- While Spring Boot abstracts much of the HTTP flow, a solid understanding of these fundamental concepts is necessary to make design, maintenance, and debugging easier.